MOSS-Audio:8B 参数挑战 30B,开源音频理解模型新标杆
MOSS-Audio:8B 参数挑战 30B,开源音频理解模型新标杆
理解一段音频,远比"把说话内容转成文字"复杂。
一段真实的音频里可能同时包含说话人的语音、背景环境音、音乐、情绪变化,甚至多人对话交叉。一个真正能用的音频理解系统,需要同时识别谁在说话、检测情绪状态、解读背景声音、分析音乐内容,还能回答"第 2 分钟说话人说了什么"这种时间感知问题。
2026 年 4 月,OpenMOSS 团队联合 MOSI.AI 与上海科技创新策源有限公司发布了 MOSS-Audio——一个将语音、环境声音、音乐理解和时间感知推理统一到一个基础模型中的开源音频理解模型。
MOSS-Audio-8B 在多项基准测试中表现超越了参数量数倍于自身的 30B 模型,在时间戳 ASR 任务上优势尤其明显。
模型家族
首发四个变体,基于 Qwen3 语言模型基座:
| 模型 | LLM 基座 | 总参数量 | 优化方向 |
|---|---|---|---|
| MOSS-Audio-4B-Instruct | Qwen3-4B | ~4.6B | 直接指令遵循 |
| MOSS-Audio-4B-Thinking | Qwen3-4B | ~4.6B | 链式推理(CoT) |
| MOSS-Audio-8B-Instruct | Qwen3-8B | ~8.6B | 直接指令遵循 |
| MOSS-Audio-8B-Thinking | Qwen3-8B | ~8.6B | 链式推理(CoT) |
Instruct 版本面向直接指令遵循,输出结构化可预测,适合生产管线集成。Thinking 版本经过链式推理训练和强化学习,多步推理任务上更强。
架构深度解析
整体架构
MOSS-Audio 采用模块化三段式设计:音频编码器 → 模态适配器 → 语言模型基座。原始音频编码为 12.5 Hz 的连续时间表示,投影到 LLM 嵌入空间后通过自回归文本生成处理。
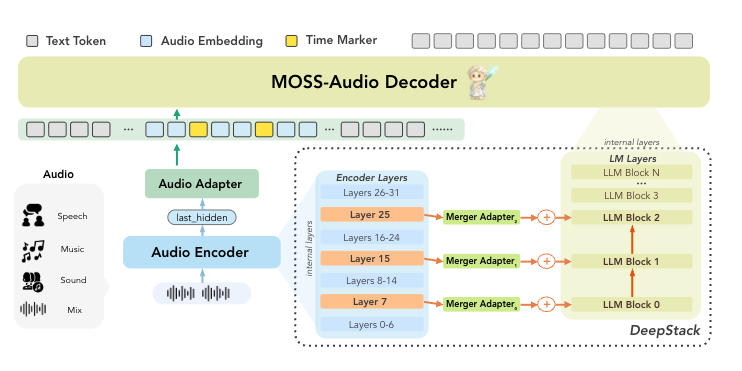
自定义音频编码器
与许多多模态模型直接使用现成前端(如 Wav2Vec2、CLAP)不同,MOSS-Audio 从 scratch 训练专用音频编码器。这一设计带来两点优势:编码器针对语音、环境声音、音乐等多个声学域联合优化,避免现成编码器在特定领域表现不佳;编码器和语言模型基座训练更协同,减少模态间隙。
DeepStack 跨层特征注入
这是 MOSS-Audio 架构中最值得关注的创新。
传统多模态架构通常只将编码器顶层输出传递给 LLM,低层声学细节(韵律、瞬态、节奏、音色、背景结构)在深层抽象过程中丢失。MOSS-Audio 采用 DeepStack 跨层注入模块:
- 选择编码器早期层和中间层特征
- 独立投影后直接注入 LLM 早期层
- 保留从低层声学细节到高层语义抽象的多粒度信息
这种设计使模型在保留语义理解能力的同时,不丢失对细微声学线索的感知。在音乐分析、情绪识别和环境声音分类中尤为关键。
时间感知表示
时间感知是音频理解区别于图像理解的核心维度。MOSS-Audio 在预训练阶段,在固定时间间隔的音频帧表示之间插入显式时间标记令牌(time-marker tokens)。
模型原生学会"什么时候发生了什么",无需额外定位头或后处理管道,即可支持时间戳 ASR、事件定位、基于时间的问答和长音频回溯。
Benchmark 表现
通用音频理解
MOSS-Audio-8B-Thinking 在四项基准上取得 71.08 的平均准确率:
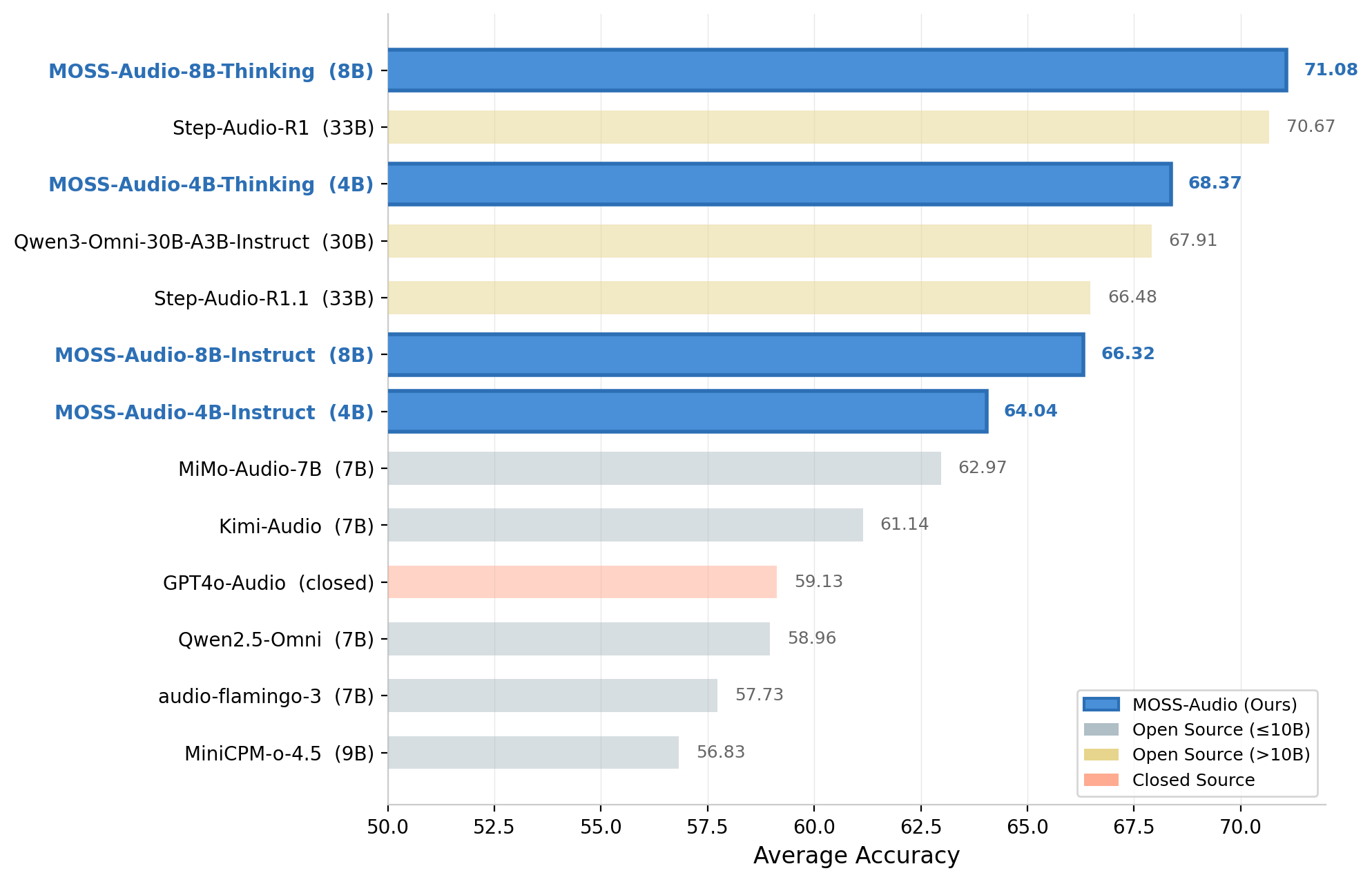
| 模型 | 规模 | MMAU | MMAU-Pro | MMAR | MMSU | 平均 |
|---|---|---|---|---|---|---|
| MOSS-Audio-8B-Thinking | 8B | 77.33 | 64.92 | 66.53 | 75.52 | 71.08 |
| Step-Audio-R1 | 33B | 78.67 | 59.68 | 69.15 | 75.18 | 70.67 |
| Qwen3-Omni-30B | 30B | 72.06 | 61.22 | 66.40 | 69.00 | 67.91 |
| MOSS-Audio-4B-Thinking | 4B | 75.78 | 63.13 | 64.83 | 73.88 | 68.37 |
MOSS-Audio-4B-Thinking(68.37)已经超越所有 7B/9B 规模的开源竞品。8B 版本在 MMAU-Pro 和 MMAR 上超过 33B 的 Step-Audio-R1。
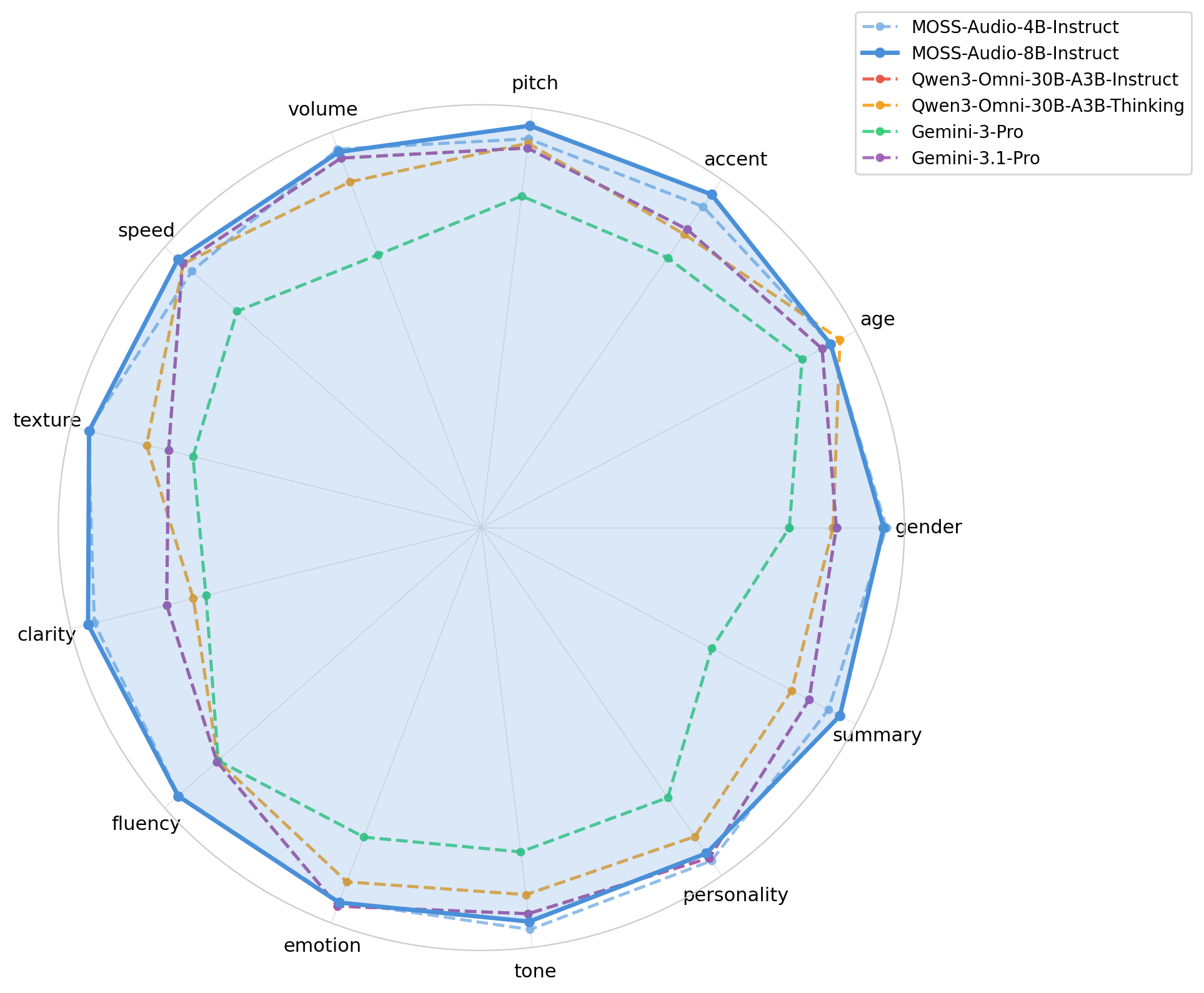
语音描述
MOSS-Audio-8B-Instruct 在语音描述任务中取得最高平均分 3.7252,在 13 个细粒度维度(性别、口音、音调、音量、音色、清晰度、流畅度、个性等)中 11 个维度领先。
ASR 性能
MOSS-Audio-8B-Instruct 以 11.30 的综合 CER(字错率)领先。在以下挑战性场景中表现突出:
- 方言识别:CER 8.76(准确率 91.24%)
- 唱歌转录:CER 9.81
- 语言切换:CER 10.18
- 非语音发声:CER 4.31
成绩不仅超越传统 ASR 模型(Paraformer、Fun-ASR、SenseVoice),也与更大多模态模型持平。
时间戳 ASR
MOSS-Audio 最亮眼的指标。时间戳 ASR 衡量模型转录音频的同时精确标注每个字词出现时间的能力:
| 模型 | AISHELL-1 (中文) | LibriSpeech (英文) |
|---|---|---|
| MOSS-Audio-8B-Instruct | 35.77 | 131.61 |
| MOSS-Audio-4B-Instruct | 76.96 | 358.13 |
| Qwen3-Omni-30B | 833.66 | 646.95 |
| Gemini-3.1-Pro | 708.24 | 871.19 |
MOSS-Audio-8B 在 AISHELL-1 上以 35.77 远超 Qwen3-Omni-30B 的 833.66,差距超过 23 倍。优势直接来自时间感知表示设计——模型原生学习时间对齐,而非依赖后处理。
核心能力
MOSS-Audio 覆盖六大能力:
- 语音与内容理解——精确转录 + 单词级/句子级时间戳对齐
- 说话人/情绪/事件分析——识别说话人特征、分析情绪状态、检测关键声学事件
- 场景/声音线索提取——从背景噪音、环境声音中推断上下文
- 音乐理解——分析音乐风格、情绪进展和乐器编排
- 音频 QA 与摘要——为播客、会议、采访生成摘要和回答问题
- 复杂推理——通过链式思维进行多跳推理
一个模型覆盖全部场景,开发者不再需要为不同音频任务拼接多个专用模型。
部署与微调
环境配置
git clone https://github.com/OpenMOSS/MOSS-Audio.git
cd MOSS-Audio
conda create -n moss-audio python=3.12 -y
conda activate moss-audio
conda install -c conda-forge "ffmpeg=7" -y
pip install --extra-index-url https://download.pytorch.org/whl/cu128 -e ".[torch-runtime]"
推理
python infer.py # 默认提示:Describe this audio.
Gradio UI
python app.py
SGLang 服务部署
git clone -b moss-audio https://github.com/OpenMOSS/sglang.git
cd sglang && pip install -e "python[all]"
sglang serve --model-path ./weights/MOSS-Audio --trust-remote-code
微调
官方提供完整微调脚本(finetune/finetune.py),支持 LoRA 和全参数微调,数据格式为 JSONL 音频-文本对话。
技术深度分析
8B 为何能挑战 30B?
MOSS-Audio 的效率优势来自三个层面。
音频编码效率。自训练编码器针对 12.5 Hz 时间分辨率优化,相比通用编码器(如 Wav2Vec2 的 50 Hz 输出),序列长度压缩约 4 倍,显著降低 LLM 输入 token 量。
跨层注入的信息密度。DeepStack 设计使 LLM 同时接收多层级特征,避免了传统架构中 LLM 需要"从零学习"低层声学特征的问题。相当于给 LLM 提供预处理的声学知识,而非原始编码表示。
时间感知的原生集成。时间标记令牌在预训练阶段就嵌入序列中,时间感知能力被编码到模型权重里,推理阶段不增加额外开销。
时间戳 ASR 差距为何如此之大?
竞争对手时间戳 ASR 性能较差,根本原因在于架构设计。Qwen3-Omni 等模型依赖后处理模块或额外定位头生成时间戳,本质上将时间对齐视为独立任务。MOSS-Audio 在预训练阶段就将时间标记嵌入序列,时间感知是核心能力而非附加功能。
这类似于原生支持多语言的模型与翻译后理解的模型之间的差距——前者在底层就建立映射,后者需要额外转换层。
Apache 2.0 许可证
MOSS-Audio 采用 Apache License 2.0 开源协议,允许商业使用、修改和分发,无 copyleft 限制。
写在最后
MOSS-Audio 的发布是开源音频理解领域的一次重要进展。8B 参数规模实现超越 30B 模型的性能,时间戳 ASR 上的数量级优势展示了架构创新的核心价值。DeepStack 跨层注入和时间感知表示两大创新,为音频-语言模型设计提供了参考。
随着微调支持和服务部署工具完善,MOSS-Audio 已经具备从研究到生产的完整链路。
相关链接
- HuggingFace:https://huggingface.co/collections/OpenMOSS-Team/moss-audio
- GitHub:https://github.com/OpenMOSS/MOSS-Audio
- OpenMOSS 官网:https://www.open-moss.com/